Since I last posted, THREE of the papers I’ve mentioned here previously have become available online! Here are their details, abstracts are below. Email me if you can’t get hold of them yourself.
Millington, J.D.A., Walters, M.B., Matonis, M.S., Laurent, E.J., Hall, K.R. and Liu, J. (2011) Combined long-term effects of variable tree regeneration and timber management on forest songbirds and timber production Forest Ecology and Management 262 718-729 doi: 10.1016/j.foreco.2011.05.002
Millington, J.D.A. and Perry, G.L.W. (2011) Multi-model inference in biogeography Geography Compass 5(7) 448-530 doi: 10.1111/j.1749-8198.2011.00433.x
Millington, J.D.A., Demeritt, D. and Romero-Calcerrada, R. (2011) Participatory evaluation of agent-based land use models Journal of Land Use Science 6(2-3) 195-210 doi:10.1080/1747423X.2011.558595
Millington, J.D.A. et al. (2011) Combined long-term effects of variable tree regeneration and timber management on forest songbirds and timber production Forest Ecology and Management 262 718-729
Abstract
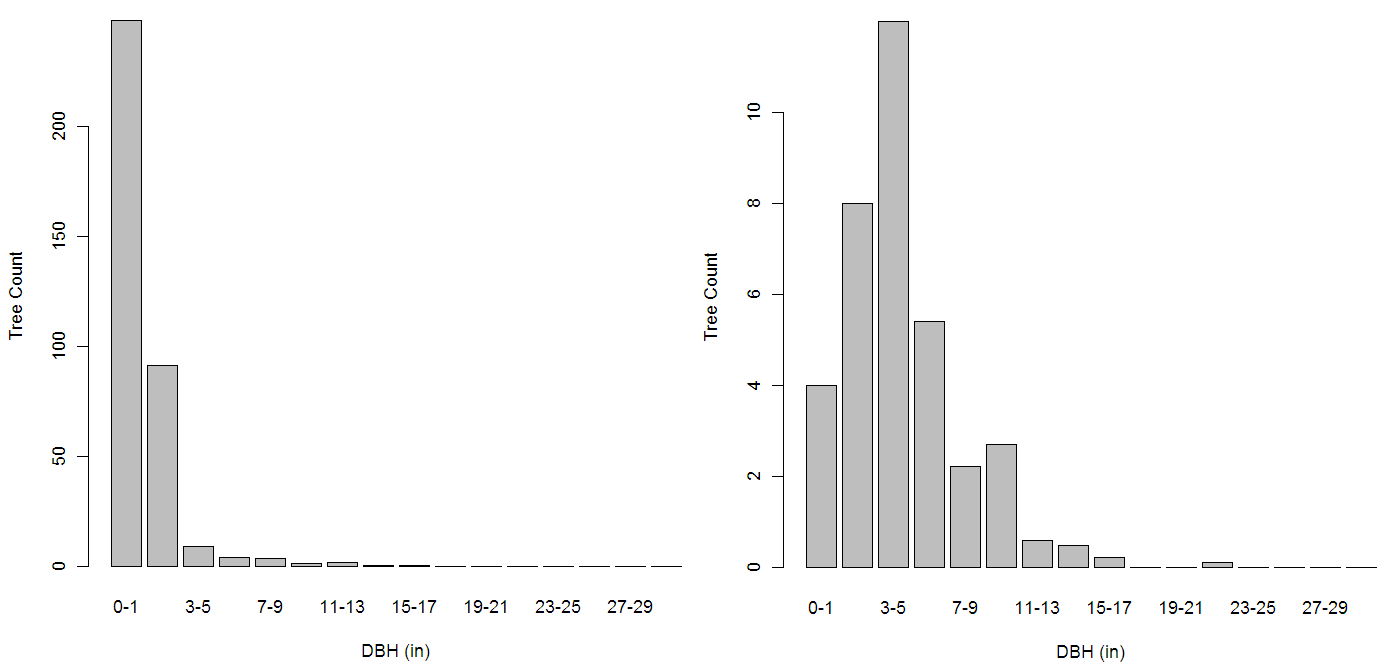
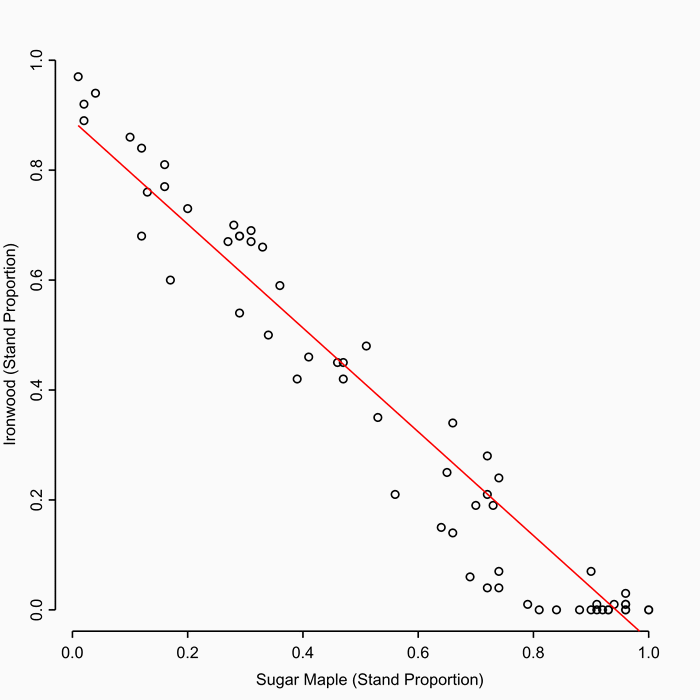
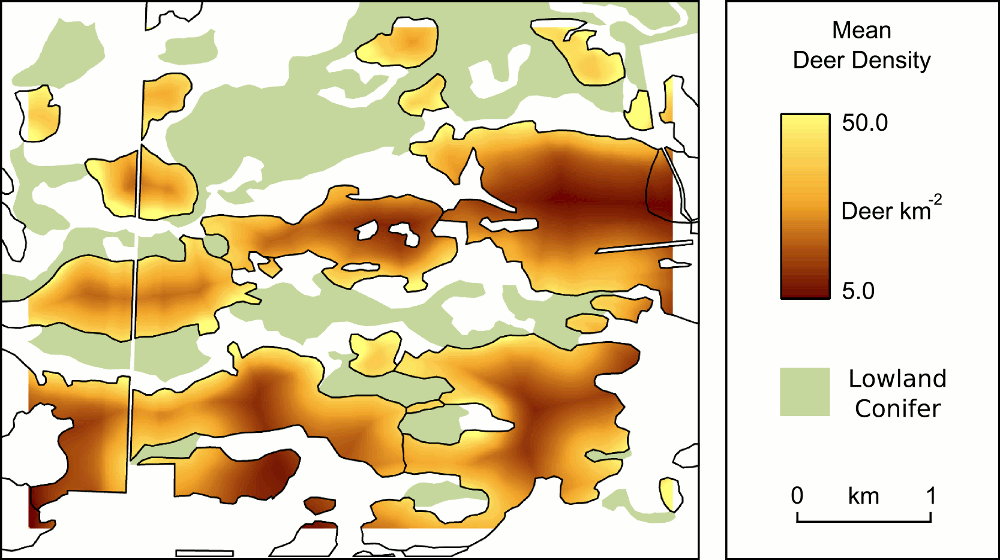
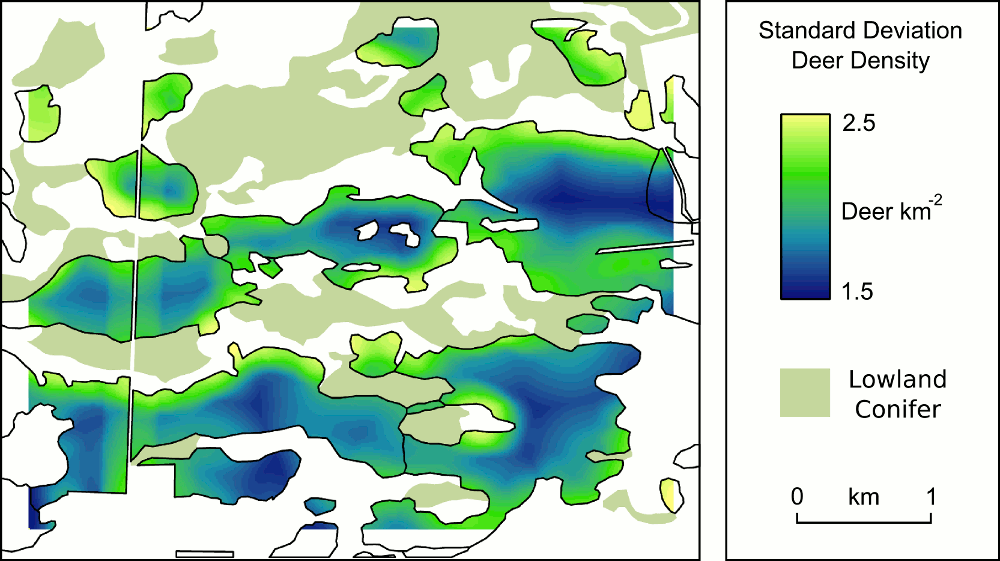
The structure of forest stands is an important determinant of habitat use by songbirds, including species of conservation concern. In this paper, we investigate the combined long-term impacts of variable tree regeneration and timber management on stand structure, songbird occupancy probabilities, and timber production in northern hardwood forests. We develop species-specific relationships between bird species occupancy and forest stand structure for canopy-dependent black-throated green warbler (Dendroica virens), eastern wood-pewee (Contopus virens), least flycatcher (Empidonax minimus) and rose-breasted grosbeak (Pheucticus ludovicianus) from field data collected in northern hardwood forests of Michigan’s Upper Peninsula. We integrate these bird-forest structure relationships with a forest simulation model that couples a forest-gap tree regeneration submodel developed from our field data with the US Forest Service Forest Vegetation Simulator (Ontario variant). Our bird occupancy models are better than null models for all species, and indicate species-specific responses to management-related forest structure variables. When simulated over a century, higher overall tree regeneration densities and greater proportions of commercially high value, deer browse-preferred, canopy tree Acer saccharum (sugar maple) than low-value, browse-avoided subcanopy tree Ostrya virginiana (ironwood) ensure conditions allowing larger harvests of merchantable timber and had greater impacts on bird occupancy probability change. Compared to full regeneration, no regeneration over 100 years reduces merchantable timber volumes by up to 25% and drives differences in bird occupancy probability change of up to 30%. We also find that harvest prescriptions can be tailored to affect both timber removal volumes and bird occupancy probability simultaneously, but only when regeneration is adequate. When regeneration is poor (e.g., 25% or less of trees succeed in regenerating), timber harvest prescriptions have a greater relative influence on bird species occupancy probabilities than on the volume of merchantable timber harvested. However, regeneration density and composition, particularly the density of Acer saccharum regenerating, have the greatest long-term effects on canopy bird occupancy probability. Our results imply that forest and wildlife managers need to work together to ensure tree regeneration density and composition are adequate for both timber production and the maintenance of habitat for avian species over the long-term. Where tree regeneration is currently poor (e.g., due to deer herbivory), forest and wildlife managers should pay particularly close attention to the long-term impacts of timber harvest prescriptions on bird species.
Millington, J.D.A. and Perry, G.L.W. (2011) Multi-model inference in biogeography Geography Compass 5(7) 448-530
Abstract
Multi-model inference (MMI) aims to contribute to the production of scientific knowledge by simultaneously comparing the evidence data provide for multiple hypotheses, each represented as a model. With roots in the method of ‘multiple working hypotheses’, MMI techniques have been advocated as an alternative to null-hypothesis significance testing. In this paper, we review two complementary MMI techniques – model selection and model averaging – and highlight examples of their use by biogeographers. Model selection provides a means to simultaneously compare multiple models to evaluate how well each is supported by data, and potentially to identify the best supported model(s). When model selection indicates no clear ‘best’ model, model averaging is useful to account for parameter uncertainty. Both techniques can be implemented in information-theoretic and Bayesian frameworks and we outline the debate about interpretations of the different approaches. We summarise recommendations for avoiding philosophical and methodological pitfalls, and suggest when each technique is best used. We advocate a pragmatic approach to MMI, one that emphasises the ‘thoughtful, science-based, a priori’ modelling that others have argued is vital to ensure valid scientific inference.
Millington et al. (2011) Participatory evaluation of agent-based land use models Journal of Land Use Science 6(2-3) 195-210
Abstract
A key issue facing contemporary agent-based land-use models (ABLUMs) is model evaluation. In this article, we outline some of the epistemological problems facing the evaluation of ABLUMs, including the definition of boundaries for modelling open systems. In light of these issues and given the characteristics of ABLUMs, participatory model evaluation by local stakeholders may be a preferable avenue to pursue. We present a case study of participatory model evaluation for an agent-based model designed to examine the impacts of land-use/cover change on wildfire regimes for a region of Spain. Although model output was endorsed by interviewees as credible, several alterations to model structure were suggested. Of broader interest, we found that some interviewees conflated model structure with scenario boundary conditions. If an interactive participatory modelling approach is not possible, an emphasis on ensuring that stakeholders understand the distinction between model structure and scenario boundary conditions will be particularly important.
")