
The main reason I haven’t blogged much recently is because all my spare time has been taken up working on revisions to a paper submitted to Environmental Modelling and Software. Provisionally entitled ‘Modelling Mediterranean Landscape Succession-Disturbance Dynamics: A Landscape Fire-Succession Model’, the paper describes the biophysical component of the coupled human-natural systems model I started developing during my PhD studies. This biophysical component is a vegetation state-and-transition model combined with a cellular-automata to represent wildfire ignition and spread.
The reviewers of the paper wanted to see some changes to the seed dispersal mechanism in the model. Greene et al. compared three commonly used empirical seed dispersal functions and concluded that the log-normal distribution is generally the most suitable approximation to observed seed dispersal curves. However, dispersal functions using an exponential function have also been used. A good example is the LANDIS forest landscape simulation model that calculates the probability of seed fall (P) in a region between the effective (ED) and maximum (MD) seed distance from the seed source. For distances from the seed source (x) < ED, P = 0.95. For x > MD, P = 0.001. For all other distances P is calculated using the negative exponential distribution function is used as follows: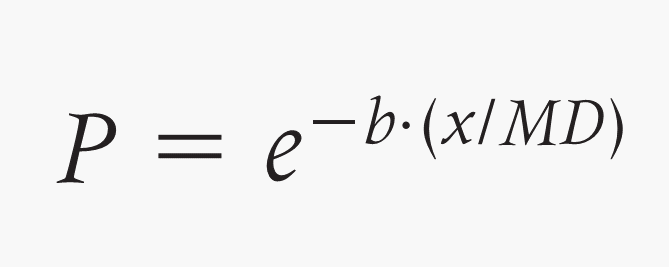 where b is a shape parameter.
where b is a shape parameter.
Recently Syphard et al. modified LANDIS for use in the Mediterranean Type Environment of California. The two predominant pine species in our study area in the Mediterran Basin have different seed types: one (Pinus pinaster) has has wings and can fly large distances (~1km), but the other (Pinus pinea) does not. In this case a negative exponential distribution is most appropriate. However, research on the dispersal of acorns (from Quercus ilex) found that the distance distribution of acorns was best modeled by a log-normal distribution. I am currently experimenting with these two alternative seed dispersal distributions and comparing them with spatially random seed dispersal (dependent upon quantity but not locations of seed sources).
The main thing that has kept me occupied the last couple of weeks has been the implementation of these approaches in a manner that is computationally feasible. I need to run and test my model over several hundred (annual) timesteps for a landscape grid of data ~1,000,000 pixels. Keeping computation time down so that model execution does not take hundreds of hours is clearly important if sufficient model executions are to be run to ensure some form of statistical testing is possible. A brute-force iteration method was clearly not the best approach.
One of my co-authors suggested I look into the use of Quadtrees. Quadtrees are a tree data structure that are often used to partition a two dimensional space by recursively subdividing regions into quadrants (nodes). A region Quadtree partitions a region of interest into four equal quadrants. Each of these quadrants is subdivided into four subquadrants, each of which is subdivided and so on to the finest level of spatial resolution required. The University of Maryland have a nice Java applet example that helps illustrate the concept.
For our seed dispersal purposes, a region quadtree with n levels of may be used to represent an landscape of 2n × 2n pixels, where each pixel is assigned a value of 0 or 1 depending upon whether it contains a seed source of the given type or not. The distance of all landscape pixels to a seed source can then be quickly calculated using this data structure – staring at the top level we work our way down the tree querying whether each quadrant contains a pixel(s) that is a seed source. In this way, large areas of the grid can be discounted as not containing a seed source, thereby speeding the distance calculation.
Now that I have my QuadTree structure in place model execution time is much reduced and a reasonable number of model executions should be possible over the next month or so of model testing, calibration and use. My next steps are concerned with pinning down the appropriate values for ED and MD in the seed dispersal functions. This process of parameterization will take into account values previously used by similar models in similar situations (e.g. Syphard et al.) and empirical research and data on species found within our study area (e.g. Pons and Pausas). The key thing to keep in mind with these latter studies is their focus on the distribution of individual seeds from individual trees – the spatial resolution of my model is 30m (i.e. each pixel is 30m square). Some translation of values for individuals versus aggregated representation of individuals (in pixels) will likely be required. Hopefully, you’ll see the results in print early next year.
