So, finally, it is done. As I write, three copies of my PhD Thesis are being bound ready for submission tomorrow! I’ve posted a short abstract below. If you want a more complete picture of what I’ve done you can look at the Table of Contents and read the online versions of the Introduction and Discussion and Conclusions. Email me if you want a copy of the whole thesis (all 81,000 words, 277 pages of it).
So just the small matter of defending the thesis at my viva voce in May. But before that I think it’s time for a celebratory beer on the South Bank of the Thames in the evening sunshine…
Modelling Land-Use/Cover Change and Wildfire Regimes in a Mediterranean Landscape
James D.A. Millington
March 2007
Department of Geography
King’s College, London
Abstract
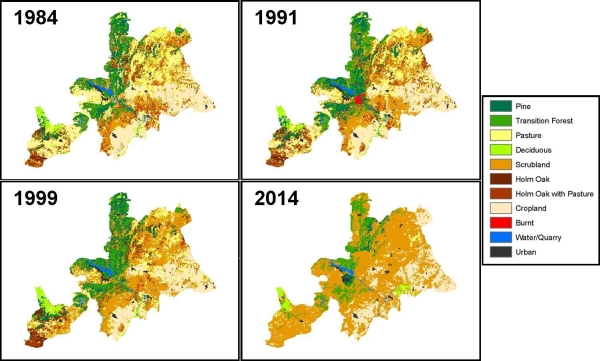
This interdisciplinary thesis examines the potential impacts of human land-use/cover change upon wildfire regimes in a Mediterranean landscape using empirical and simulation models that consider both social and ecological processes and phenomena. Such an examination is pertinent given contemporary agricultural land-use decline in some areas of the northern Mediterranean Basin due to social and economic trends, and the ecological uncertainties in the consequent feedbacks between landscape-level patterns and processes of vegetation- and wildfire-dynamics.
The shortcomings of empirical modelling of these processes are highlighted, leading to the development of an integrated socio-ecological simulation model (SESM). A grid-based landscape fire succession model is integrated with an agent-based model of agricultural land-use decision-making. The agent-based component considers non-economic alongside economic influences on actors’ land-use decision-making. The explicit representation of human influence on wildfire frequency and ignition in the model is a novel approach and highlights biases in the areas of land-covers burned according to ignition cause. Model results suggest if agricultural change (i.e. abandonment) continues as it has recently, the risk of large wildfires will increase and greater total area will be burned.
The epistemological problems of representation encountered when attempting to simulate ‘open’, middle numbered systems – as is the case for many ‘real world’ geographical and ecological systems – are discussed. Consequently, and in light of recent calls for increased engagement between science and the public, a shift in emphasis is suggested for SESMs away from establishing the truth of a model’s structure via the mimetic accuracy of its results and toward ensuring trust in a model’s results via practical adequacy. A ‘stakeholder model evaluation’ exercise is undertaken to examine this contention and to evaluate, with the intent of improving, the SESM developed in this thesis. A narrative approach is then adopted to reflect on what has been learnt.