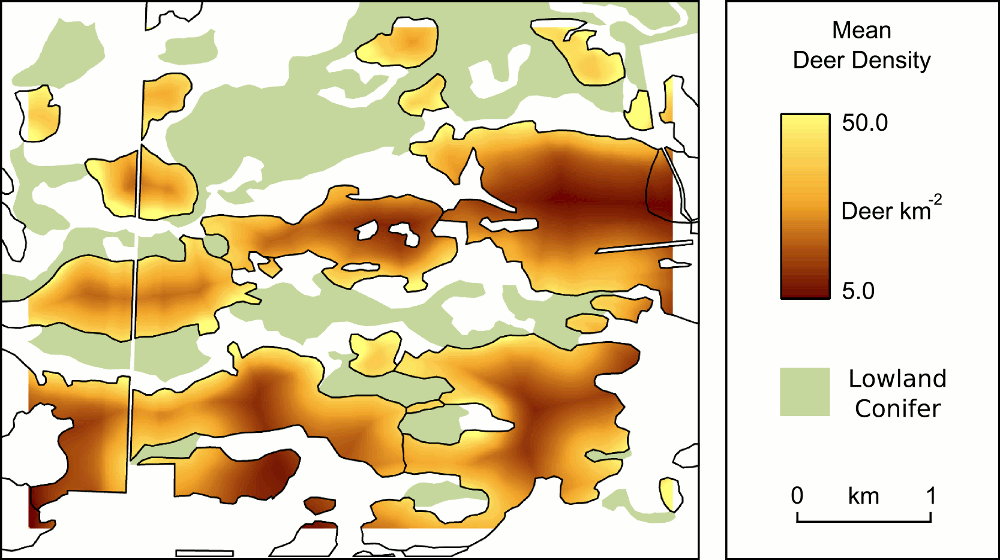
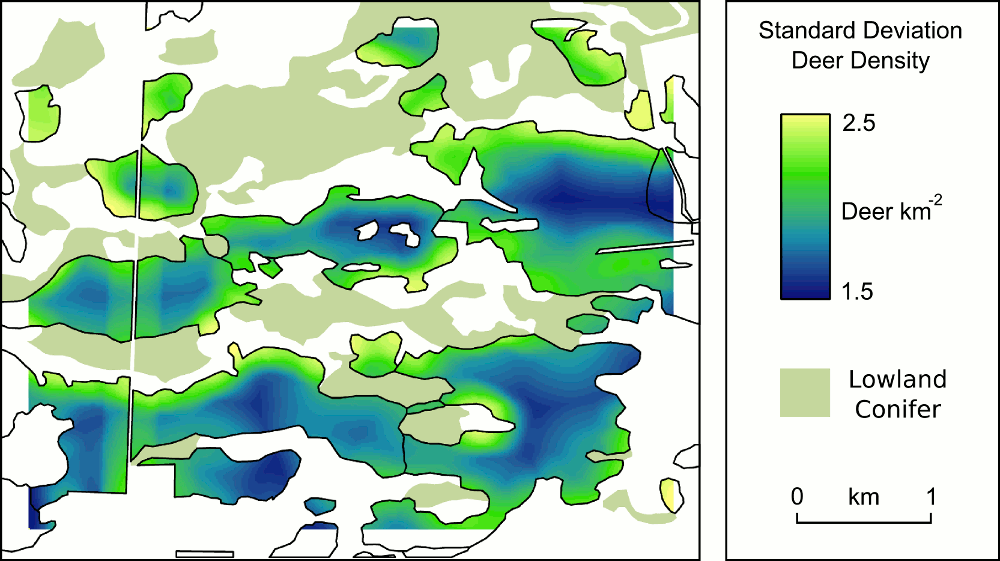
Birds have been given short shrift in my posts blog posts about the Michigan UP ecological-economic modelling project. It’s not that we have forgotten about them, it’s just that before we got to incoporating them into our modelling there were other things to deal with first. Now that we’ve made progress on modelling deer distribution it’s time to turn our attention to how we can represent the potential impacts of forest management on bird habitat so that we might better understand the tradeoffs that will need to be negotiated to achieve both economic and ecological sustainability.
")
One of the things we want to do is link our bird-vegetation modelling with Laila Racevskis‘ assessment of the economic value of bird species she did during her PhD research. Laila assessed local residents’ willingess-to-pay for ensuring the conservation of several bird species of concern in our study area. If we can use our model to examine the effects of different timber management plans (each yielding different timber volumes) on the number of bird species present in an area we can use Laila’s data to examine the economic tradeoffs between different management approaches. The first thing we need to do to achieve this is be able to estimate how many bird species would be present in a given forest stand.
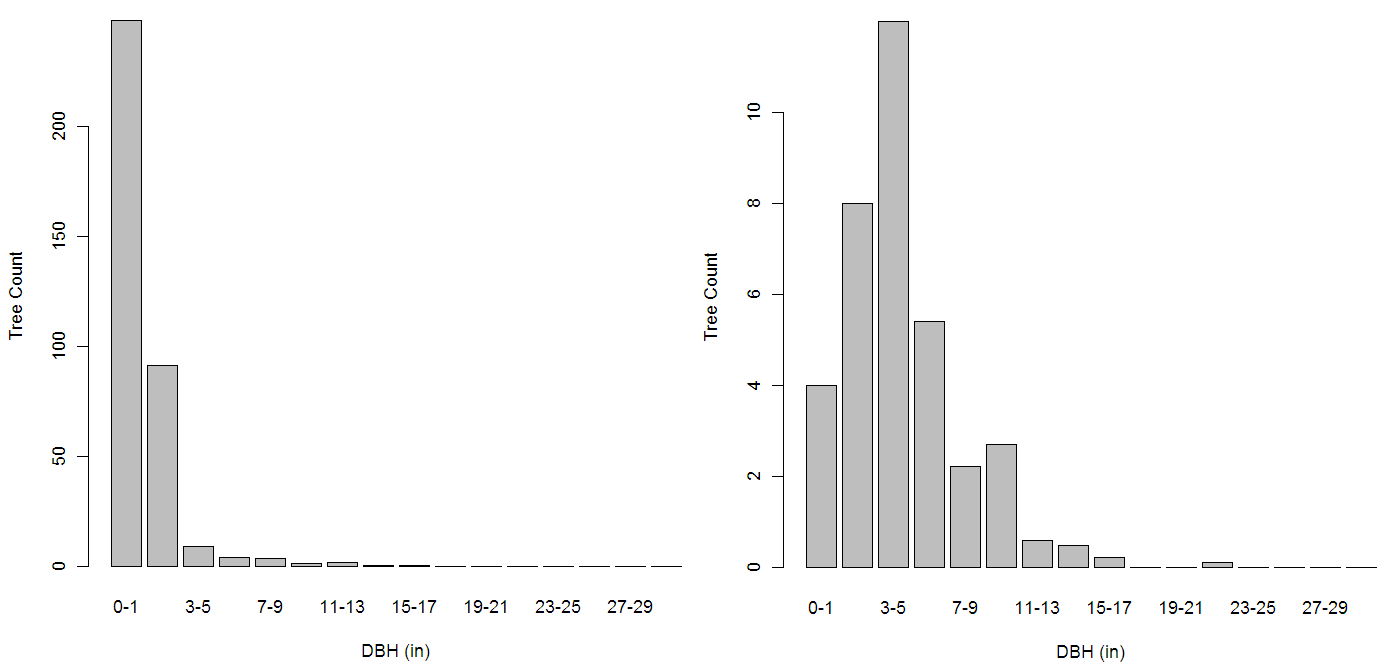
Right now the plan is to estimate the presence of songbird species of concern in forest stands by using the data Ed Laurent collected during his PhD research at MSU. To this end I’ve been doing some reading on the latest occupancy modelling approaches and reviewing the literature on its application to birds in managed forests. Probably the most popular current approach was developed recently by Darryl Mackenzie and colleagues – it allows the the estimation of whether a site is occupied by a given species or not when we know that our detection is imperfect (i.e. when we know we have false negative observations in our bird presence data). The publication of some nice overviews of this approach (e.g. Mackenzie 2006) plus the development of software to perform the analyses are likely to be at the root of this popularity.
The basic idea of the approach is that if we are able to make multiple observations at a site (and if we assume that bird populations and habitat do not change between these observations) we can use the probability of each bird observation history at a site across all the sites to form a model likelihood. This likelihood can then be used to estimate the parameters using any likelihood-based estimation procedure. Covariates can be used to model both the probability of observation and detection (i.e. we can account for factors that may have hindered bird observation such a wind strength or the time of day). I won’t go into further detail here because there’s an excellent online book that will lead you through the modelling process, and you can download the software and try it yourself.
Two recent papers have used this approach to investigate bird species presence given different forest conditions. DeWan et al. 2009 used Mackenzie’s occupancy modelling approach to examine impacts of urbanization on forest birds in New York State (they do a good job of explaining how they apply Mackenzie’s approach to their data and study area). DeWan considered landscape variables such as perimeter-area ratios of habitat patches and proximity to urban area to create occupancy models for 9 birds species at ~100 sites. They found that accounting for imperfect bird detection was important and that habitat patch “perimeter-area ratio had the most consistent influence on both detection probability and occupancy” (p989).
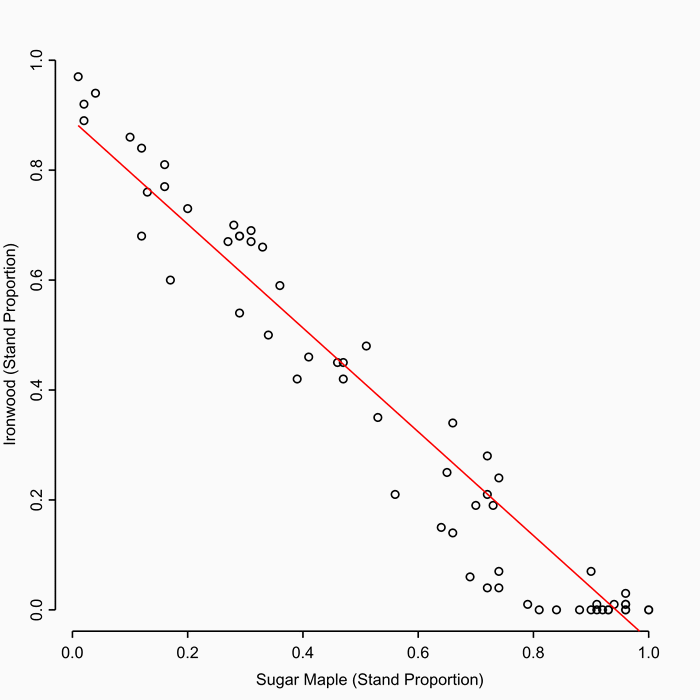
In a slightly different approach Smith et al. 2008 estimated site occupancy of the black-throated blue warbler (Dendroica caerulescens) and ovenbird (Seiurus aurocapillus) in 20 northern hardwood-conifer forest stands in Vermont. At each bird observation site they had also collected stand structure variables including basal area, understory density and tree diameters (in contrast to DeWan et al who only considered landscape-level variables). Smith et al. write their results “demonstrate that stand-level forest structure can be used to predict the occurrence of forest songbirds in northern hardwood-conifer forests” (p43) and “suggest that the role of stand-level vegetation may have been underestimated in the past” (p36).
Our approach will take the best aspects from both these studies; the large sample size of DeWan et al. with the consideration of stand-level variables like Smith et al. More on this again soon I expect.